

A Beginner’s Guide : How to Extract Text from PDFs?

Summary
Learn how to extract text from PDF files with ease using free tools and OCR technology. This guide covers manual and automated methods, providing practical solutions for anyone wondering 'How to Extract Text from PDF'.

Table of contents

Steps to Copy and Paste Text page by page


Copying PDF text results in garbled characters
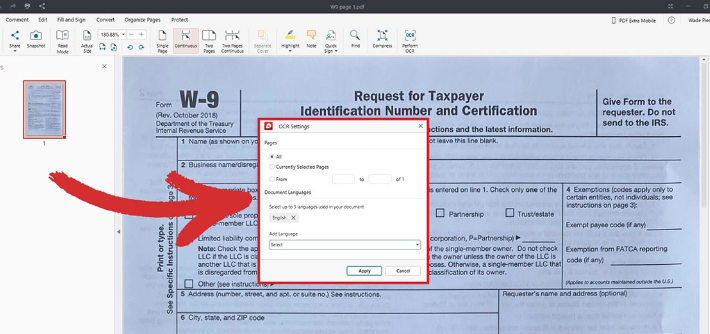
Scanned PDF files

Convert to Editable Convert to Word/Excel/PPT/Text/Image/Html/Epub
Multifunctional Encrypt/decrypt/split/merge/add watermark
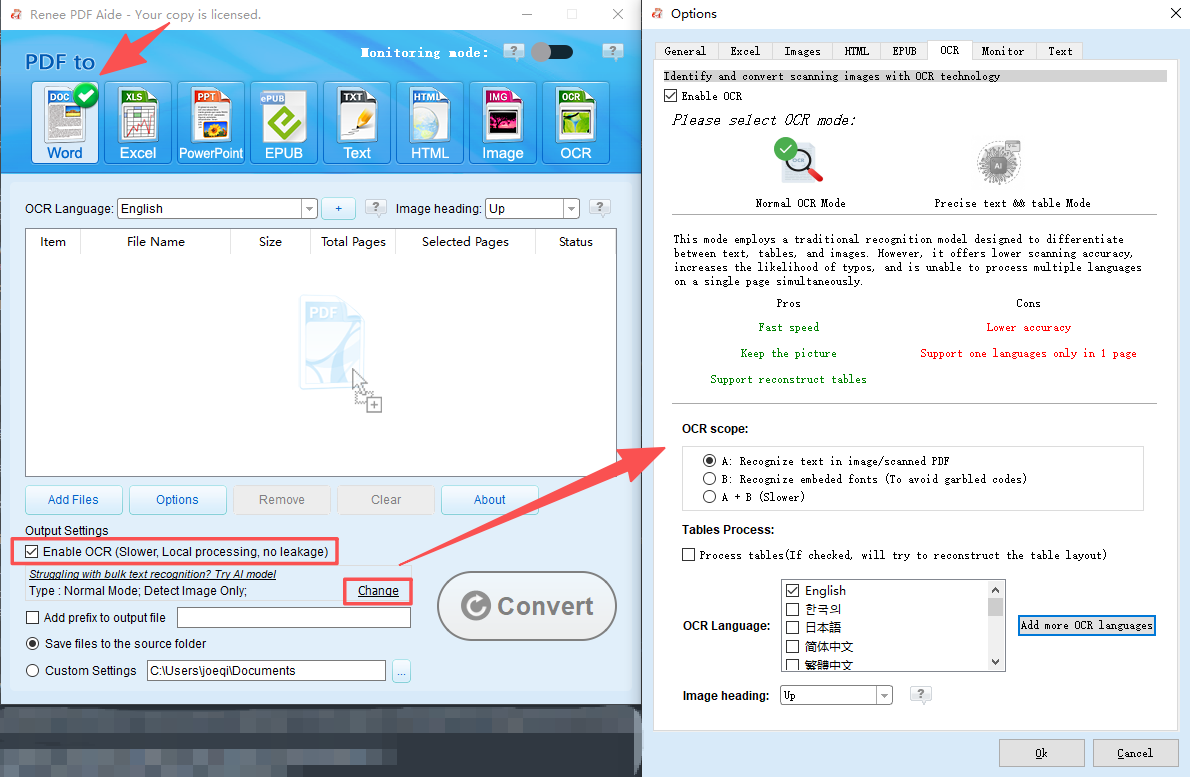
OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
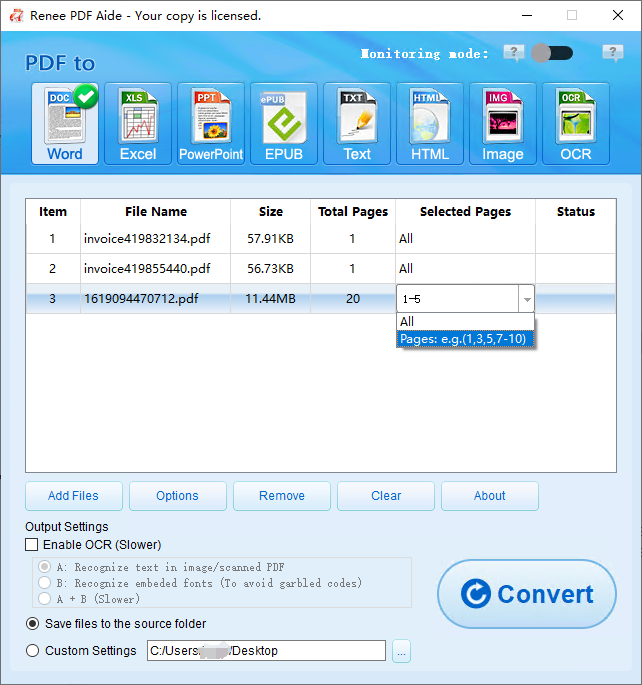
Quick Convert dozens of PDF files in batch
Compatible Support Windows 11/10/8/8.1/Vista/7/XP/2K
Convert to Editable Word/Excel/PPT/Text/Image/Html/Epub
OCR Support Extract Text from Scanned PDFs, Images & Embedded
Support Windows 11/10/8/8.1/Vista/7/XP/2K
How to Use AI for Text Extraction
<span style="color: #0f1115;">Extract all text from this image and do not summarize the text. </span>
Extract all text from this pdf file.

In many cases, users must manually capture screenshots page by page, which is time-consuming and error-prone. For larger workloads or professional use, dedicated desktop software remains the more reliable and efficient choice.
📊 PDF Handling: Free vs. Paid Plans (2025 Update)
| Platform | Free Version | Paid / Premium Version | PDF Conversion Support | Output Formats | 2025 AI-OCR Enhancements |
|---|---|---|---|---|---|
Microsoft Copilot | Upload PDFs up to 50 pages; split large files. Integrates with Edge for quick OCR. | Microsoft 365: Unlimited pages, AI-powered table extraction. | ❌ No direct conversion, but exports to JSON via API. | Plain text, JSON | Cognitive Services v3.1: 98% accuracy for scanned docs. |
ChatGPT (OpenAI) | No direct upload; paste text or screenshot. | Plus/Team: Upload up to 300 pages; auto-OCR for images. | ❌ Summarizes only; use plugins for export. | Plain text, bullet lists | LlamaParse integration: Handles multilingual PDFs (e.g., English+Hindi). |
Grok (xAI) | Upload ~50 pages; semantic search for text. | Premium: ~200 pages, batch processing. | ❌ Plain text only. | Plain text | Enhanced OCR for low-quality scans; privacy-focused. |
What is Renee PDF Aide?
Convert to Editable Convert to Word/Excel/PPT/Text/Image/Html/Epub
Multifunctional Encrypt/decrypt/split/merge/add watermark
OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
Quick Convert dozens of PDF files in batch
Compatible Support Windows 11/10/8/8.1/Vista/7/XP/2K
Convert to Editable Word/Excel/PPT/Text/Image/Html/Epub
OCR Support Extract Text from Scanned PDFs, Images & Embedded
Support Windows 11/10/8/8.1/Vista/7/XP/2K
Extract Text to Word


Extract Text to Excel
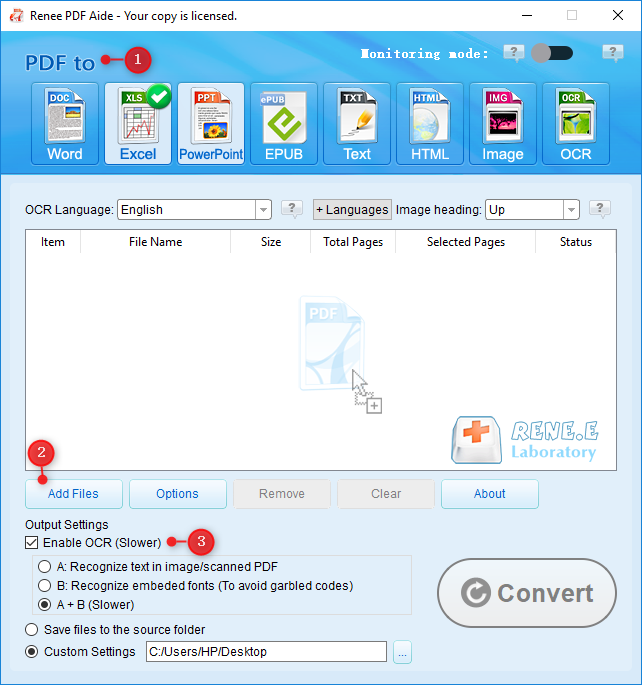
Extract Text to PowerPoint
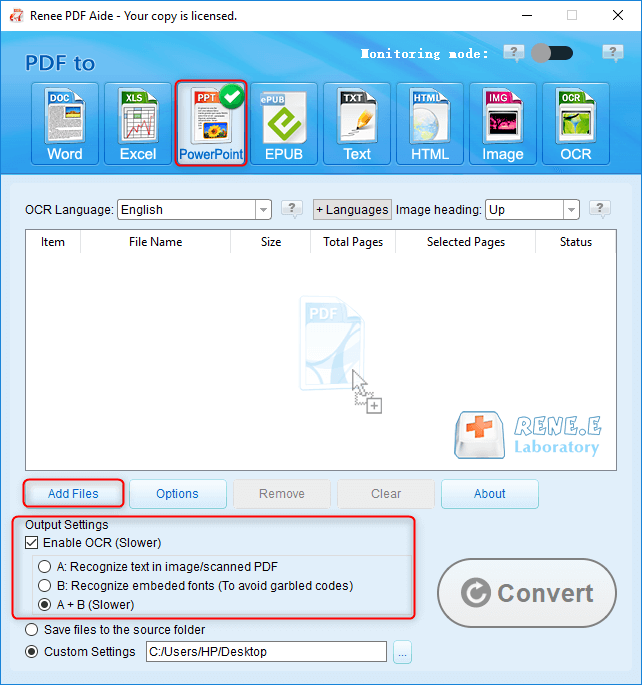
Extract Text to TXT
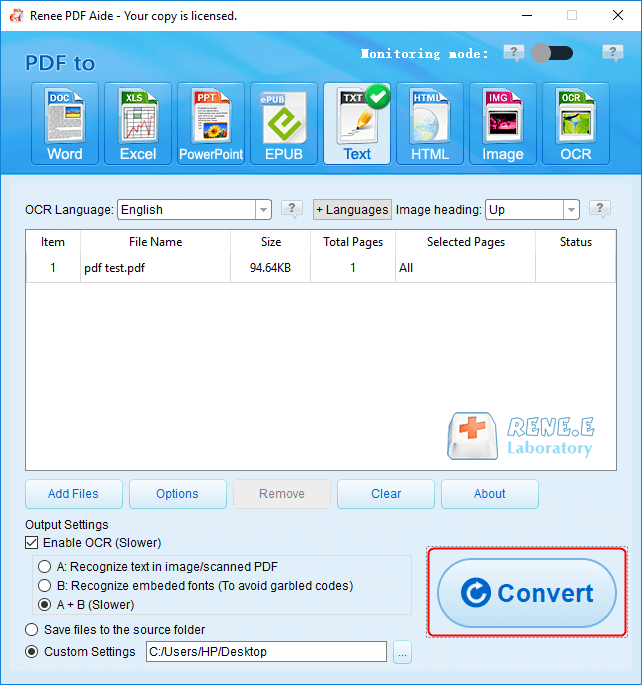

| Tool | Features | Limitations |
|---|---|---|
PDF Candy | Free PDF-to-TXT conversion, auto OCR for scanned files, user-friendly interface. Ideal for extracting product lists from catalogs. | File size limits (~100MB), ads in free version, slower during peak times, privacy risks from server uploads. |
PDF2Go | No registration needed, supports mobile, fast TXT conversion with OCR. Great for quick notes from meeting PDFs. | Limited file size, potential data exposure, occasional formatting loss, internet required. |
Python Script Example
pip install PyMuPDF tesserocr python-docx Pillow
import os
import fitz # PyMuPDF
import pytesseract
from PIL import Image
from docx import Document
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract_text_to_file(pdf_path, output_format="txt", lang="eng"):
try:
doc = fitz.open(pdf_path)
text_output = []
for page_num, page in enumerate(doc, start=1):
text = page.get_text().strip()
if text:
text_output.append(f"--- Page {page_num} ---\n{text}\n")
else:
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
ocr_text = pytesseract.image_to_string(img, lang=lang)
text_output.append(f"--- Page {page_num} (OCR) ---\n{ocr_text}\n")
doc.close()
output_file = f"{os.path.splitext(pdf_path)[0]}.{output_format}"
full_text = "\n".join(text_output)
if output_format == "txt":
with open(output_file, "w", encoding="utf-8") as f:
f.write(full_text)
elif output_format == "docx":
docx = Document()
docx.add_paragraph(full_text)
docx.save(output_file)
else:
raise ValueError("Unsupported output format. Use 'txt' or 'docx'.")
return output_file
except Exception as e:
print(f"Error processing PDF: {e}")
return None
if __name__ == "__main__":
pdf_file = "sample.pdf"
result = extract_text_to_file(pdf_file, output_format="txt", lang="eng+hin")
if result:
print(f"Text extracted to: {result}")
✅ Pros: Free, customizable
❌Cons: Requires setup
hin+eng for accurate OCR. Save as TXT for plain text or Word for formatted editing.| User Type | Best Method | Pros | Next Action |
|---|---|---|---|
Beginner | Copy-Paste or Online Tools | Simple, no cost or skills needed. | Open your PDF in Foxit Reader today. |
Professional | Renee PDF Aide | Fast conversions to Word/Excel, secure offline. | Download trial from official site. |
Tech-Savvy | Python with OCR | Automated, scalable for big data. | Install dependencies and test the code. |
Mobile User | AI Assistants | Works anywhere with internet. | Try ChatGPT Plus for uploads. |
What if the extracted text is garbled or incomplete?
Are online tools safe for sensitive PDFs?
Can I extract text from encrypted PDFs?
How do I handle large PDFs (e.g., 500+ pages)?
How do I extract text from multilingual PDFs?
hin+eng) for accurate extraction from bilingual PDFs.Does text extraction keep the original PDF formatting?
Relate Links :
A Beginner’s Guide : How to Extract Text from PDFs?

02-10-2025
Amanda J. Brook : Learn how to extract text from PDF files with ease using free tools and OCR technology. This guide...
Extracting Text from PDF to Excel: A Comprehensive Guide

23-04-2025
Jennifer Thatcher : The article provides a comprehensive guide on extracting text data from PDFs to Excel, addressing the challenges of...
Convert Scanned PDF to TXT: Easy Steps for Text Extraction
31-05-2024
Jennifer Thatcher : Learn how to convert scanned PDF files to TXT format to easily copy and use the text in...
Why Renee PDF Aide’s OCR Requires AVX?
25-08-2025
Amanda J. Brook : Learn how AVX (Advanced Vector Extensions) powers Renee PDF Aide’s OCR for faster and more accurate text extraction,...


User Comments
Leave a Comment