

PDF to DOCX Python: Batch Conversion Scripts, Libraries & Reliable Tools

Summary
The article examines pdf to docx python conversion methods, covering Python libraries like pdf2docx and PyMuPDF as well as dedicated desktop tools. It highlights batch processing scripts, OCR capabilities, and automated folder monitoring solutions for reliable document workflows.

| Issue Type | Typical Cause | Pre-check / Diagnosis |
|---|---|---|
Scanned PDFs | No selectable text | Open the PDF and try highlighting text; if nothing highlights, OCR is required |
Complex tables/layouts | pdf2docx doesn’t have a layout engine | Convert one page first and check for shifted columns |
Embedded fonts / garbled text | Font subsetting or non-standard encoding | Scan the DOCX for □ or random symbols |
Large batch crashes | Memory or dependency conflicts | Test with 5–10 files; keep an eye on RAM usage |

| Approach | Best For | Key Limitation |
|---|---|---|
pdf2docx | Quick conversions of digital PDFs | Weak with complex layouts; no OCR |
PyMuPDF + python-docx | Full control and custom extraction logic | Requires heavy coding for layout reconstruction |
pdfplumber | Table‑centric PDFs | No DOCX output; text extraction only |
Pandoc | Scriptable pipelines; multi‑format workflows | PDF→DOCX quality depends on LaTeX/PDF readers |
LibreOffice CLI | Batch automation; headless conversion | Layout fidelity varies; no OCR |
| Feature | Support |
|---|---|
Direct PDF→DOCX | Yes |
OCR | No |
Embedded Fonts | Partial |
Complex Layouts | Moderate |
Automation | Yes |
XFA Forms | No |
| Feature | Support |
|---|---|
Direct PDF→DOCX | No (manual coding) |
OCR | No (external OCR needed) |
Embedded Fonts | Read only |
Complex Layouts | High control, manual |
Automation | Excellent |
XFA Forms | No |
| Feature | Support |
|---|---|
Direct PDF→DOCX | No |
OCR | No |
Embedded Fonts | No |
Complex Layouts | Good for tables |
Automation | Yes |
XFA Forms | No |
| Feature | Support |
|---|---|
Direct PDF→DOCX | Yes (via LaTeX) |
OCR | No |
Embedded Fonts | No |
Complex Layouts | Limited |
Automation | Excellent |
XFA Forms | No |
| Feature | Support |
|---|---|
Direct PDF→DOCX | Yes |
OCR | No |
Embedded Fonts | Partial |
Complex Layouts | Moderate |
Automation | Excellent |
XFA Forms | No |

Convert to Editable Convert to Word/Excel/PPT/Text/Image/Html/Epub
Multifunctional Encrypt/decrypt/split/merge/add watermark
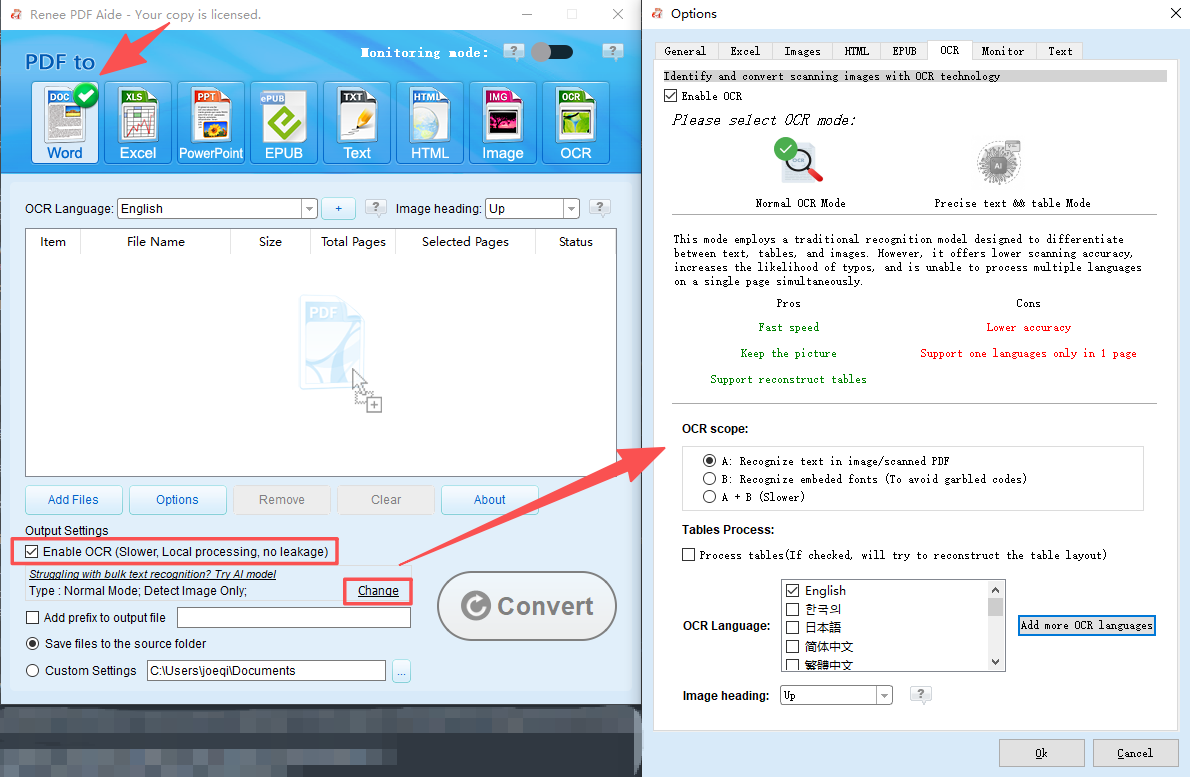
OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
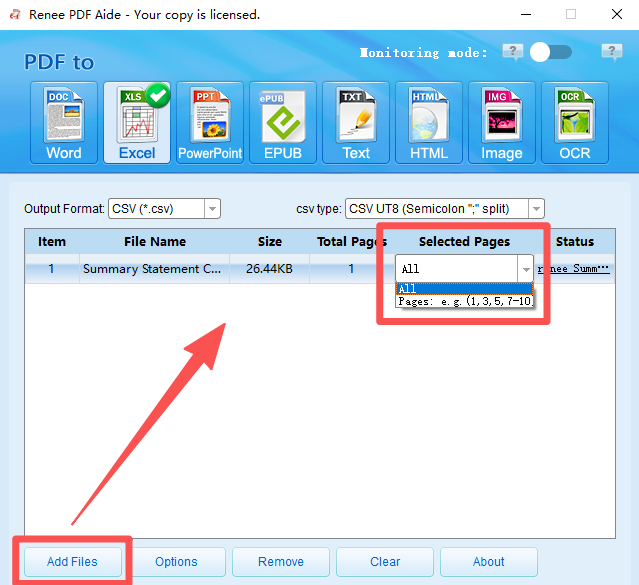
Quick Convert dozens of PDF files in batch
Compatible Support Windows 11/10/8/8.1/Vista/7/XP/2K
Convert to Editable Word/Excel/PPT/Text/Image/Html/Epub
OCR Support Extract Text from Scanned PDFs, Images & Embedded
Support Windows 11/10/8/8.1/Vista/7/XP/2K
Key advantages include



Convert to Editable Convert to Word/Excel/PPT/Text/Image/Html/Epub
Multifunctional Encrypt/decrypt/split/merge/add watermark
OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
Quick Convert dozens of PDF files in batch
Compatible Support Windows 11/10/8/8.1/Vista/7/XP/2K
Convert to Editable Word/Excel/PPT/Text/Image/Html/Epub
OCR Support Extract Text from Scanned PDFs, Images & Embedded
Support Windows 11/10/8/8.1/Vista/7/XP/2K
Steps
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
Limitations
- Complete code control and customization
- Free to use for simple native PDFs
- Easy integration into existing Python pipelines
Disadvantages:
- No built-in OCR for scanned documents
- Complex tables and images often misalign
- Requires external tools for scheduled execution
- Heavy debugging needed for different PDF layouts
| Use Case | Recommended Tool |
|---|---|
Quick test on 1–2 simple PDFs | Python pdf2docx script |
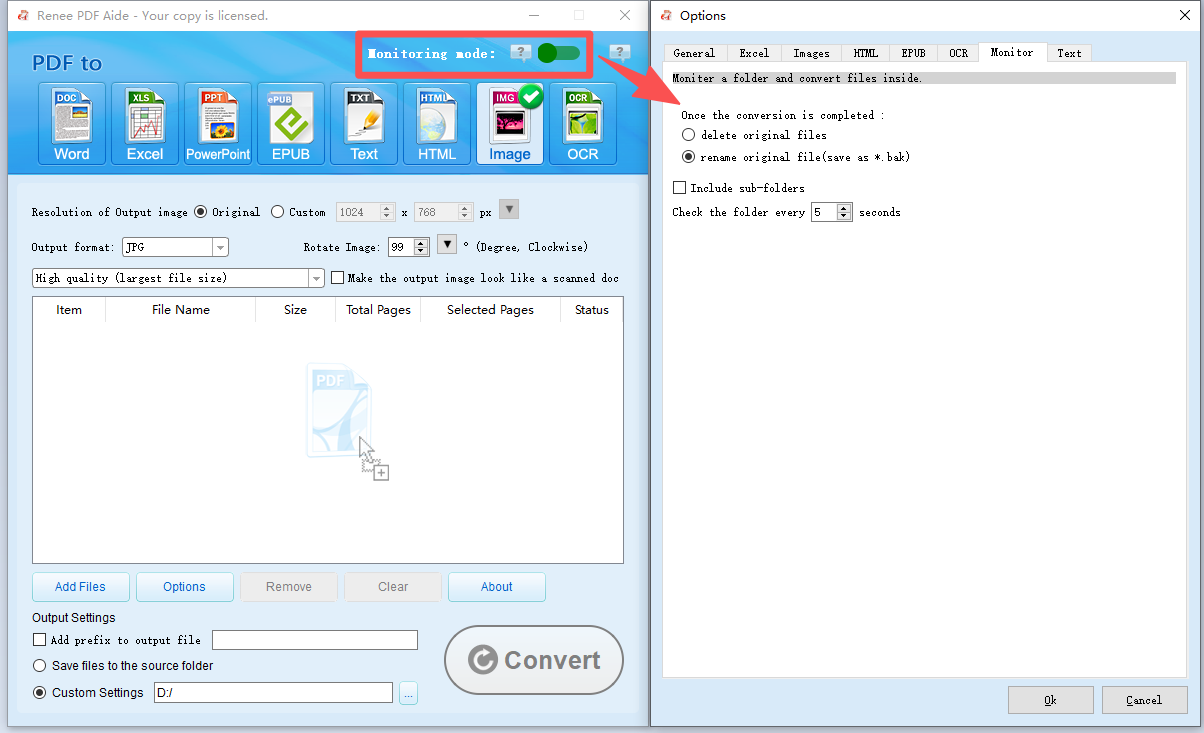
Scanned PDFs or complex layouts | Renee PDF Aide with OCR |
Batch conversion (50+ files) | Renee PDF Aide (batch + monitoring mode) |
Scheduled nightly conversions | Renee PDF Aide monitoring mode |
Full code control + simple PDFs | PyMuPDF + watchdog custom script |
Can Renee PDF Aide handle scanned PDFs that Python scripts cannot read?
Why does pdf2docx lose my table formatting or column alignment?
What is the maximum batch size or page limit in Renee PDF Aide?
Can I convert password-protected PDFs to DOCX with Python or Renee PDF Aide?
Does Renee PDF Aide work with XFA forms (bank/government PDFs)?

Convert to Editable Convert to Word/Excel/PPT/Text/Image/Html/Epub
Multifunctional Encrypt/decrypt/split/merge/add watermark
OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
Quick Convert dozens of PDF files in batch
Compatible Support Windows 11/10/8/8.1/Vista/7/XP/2K
Convert to Editable Word/Excel/PPT/Text/Image/Html/Epub
OCR Support Extract Text from Scanned PDFs, Images & Embedded
Support Windows 11/10/8/8.1/Vista/7/XP/2K
Relate Links :
Top Ways to Extract Tables from PDF Files : Free & AI Tools Revealed

28-10-2025
Amanda J. Brook : Discover the best ways to extract tables from PDF in 2025 using free tools and advanced AI methods,...
A Beginner’s Guide : How to Extract Text from PDFs?

02-10-2025
Ashley S. Miller : Learn how to extract text from PDF files with ease using free tools and OCR technology. This guide...


User Comments
Leave a Comment