

Top Ways to Extract Tables from PDF Files : Free & AI Tools Revealed

Summary
Discover the best ways to extract tables from PDF in 2025 using free tools and advanced AI methods, perfect for professionals in the US and India. Get precise, secure conversions of PDF tables to Excel, CSV, Markdown, and more.


- Excel (*.xlsx)
- CSV (*.csv) (perfect for databases and data analysis)
- Markdown (ideal for AI training data or documentation)
- TXT files
- Editable Word documents
- …and many other formats.


Versatile Convert to Word/Excel/PPT/Text/Image/Html/Epub
Secure 100% local conversions ensure zero risk of data leaks
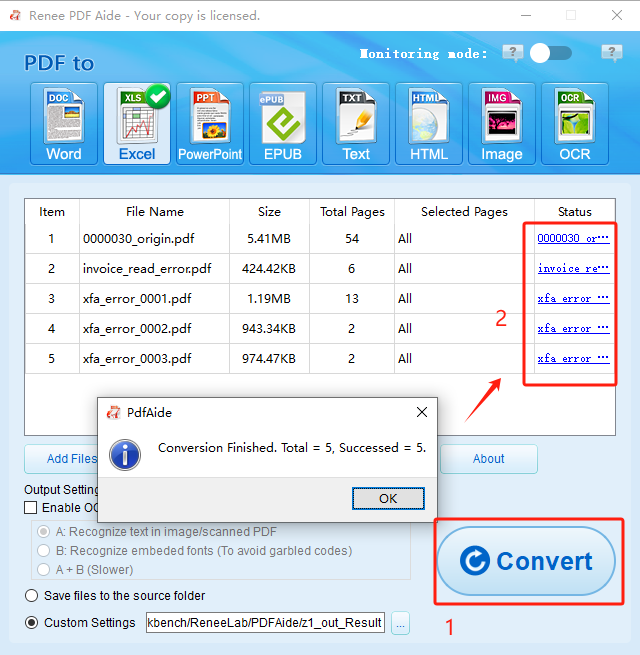
Efficient Batch Process dozens of PDF files in seconds
Comprehensive Seamlessly convert PDFs to Excel, PowerPoint, Text, and more
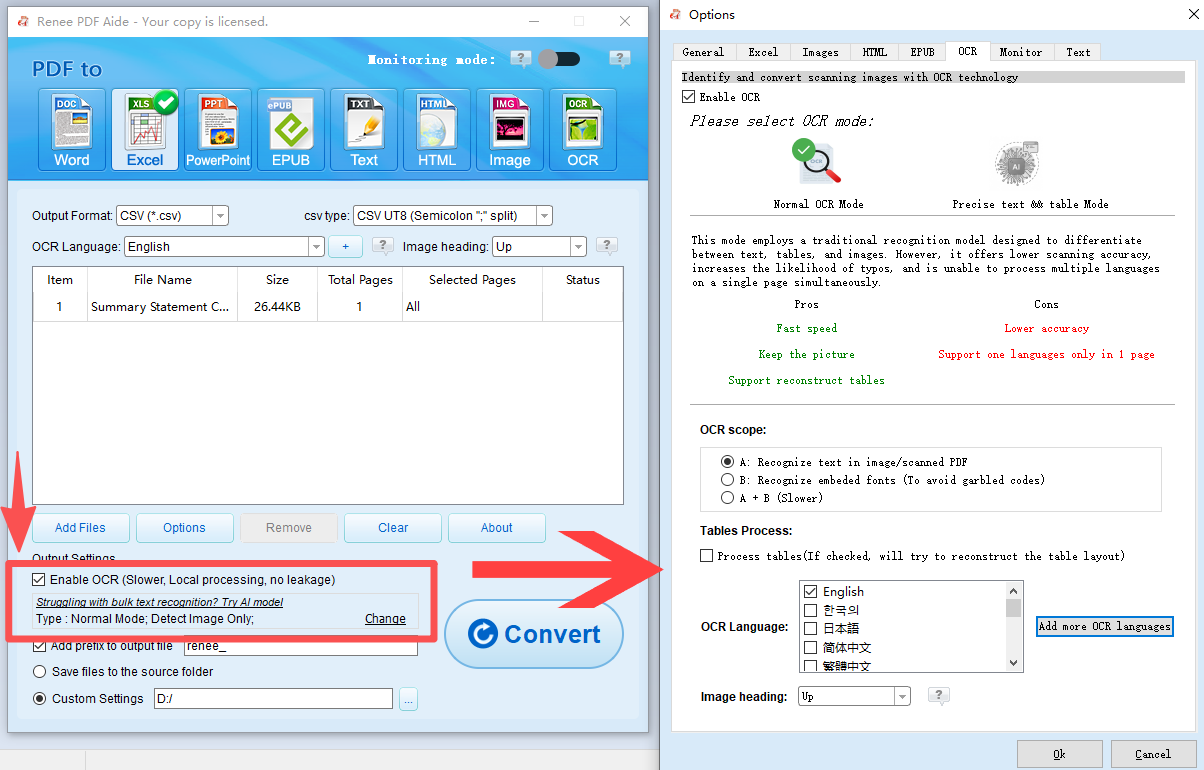
OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
Versatile Effortlessly convert XFA, multi
Secure 100% local conversions ensure zero risk of data leaks
Efficient Batch Process dozens of PDF files in seconds
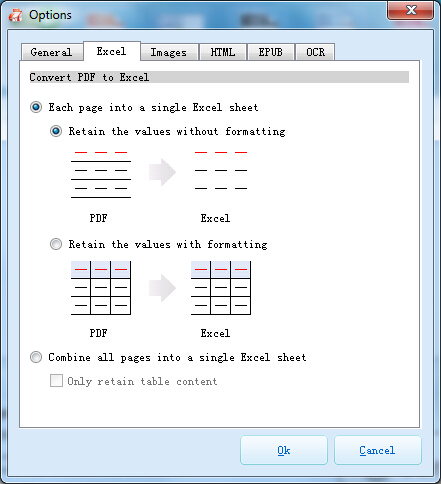
How to Extract Tables Using Renee PDF Aide

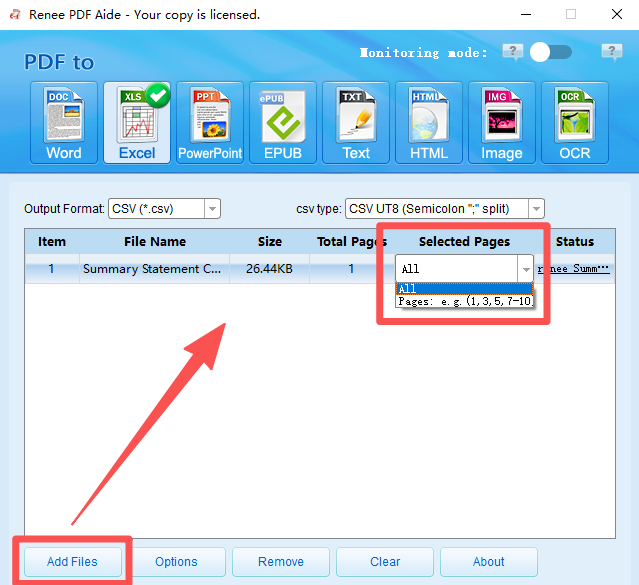
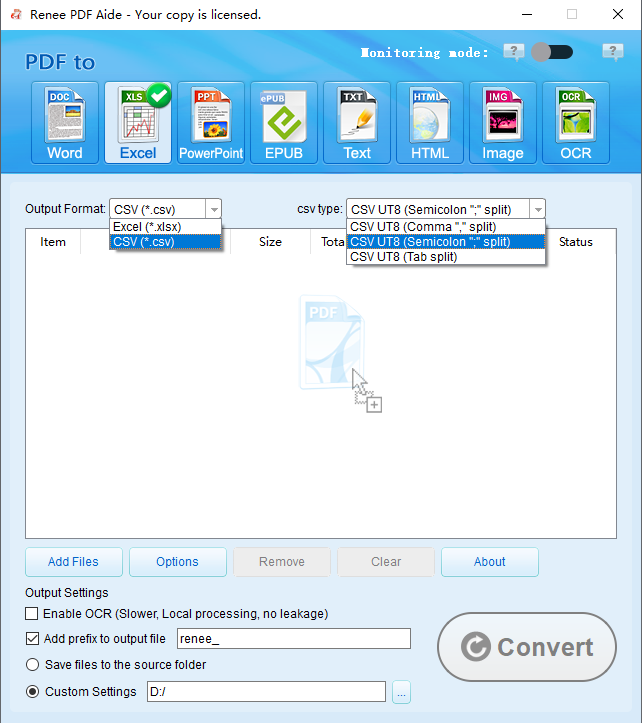
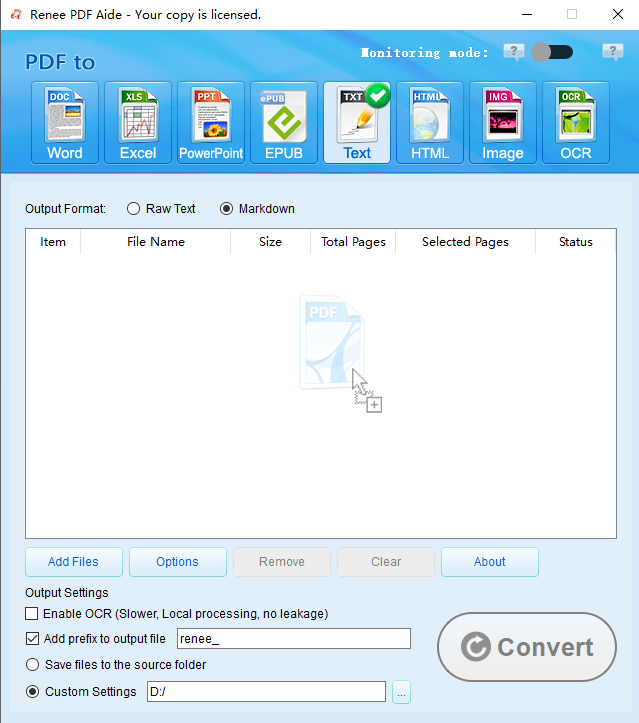
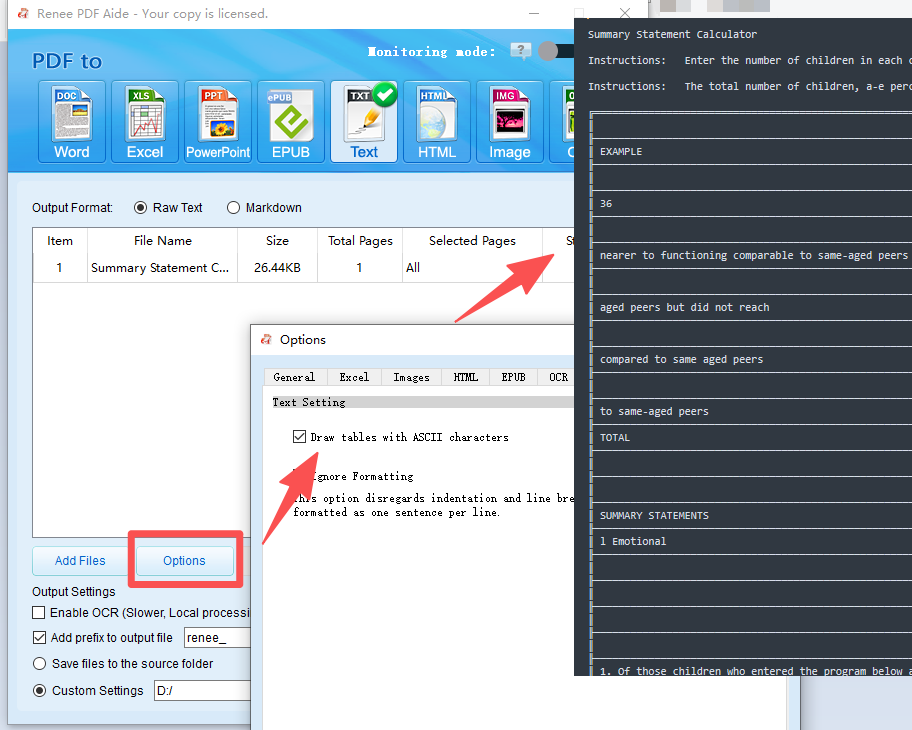
- Completely free and open-source.
- Runs locally, ensuring 100% data privacy.
- Simple interface for visually selecting tables.
- Exports to CSV, a universally compatible format.
Disadvantages:
- Does not work on scanned (image-based) PDFs.
- May struggle with complex tables, merged cells, or unusual layouts.
- Requires Java to be installed on your system.
- No longer actively maintained, so bugs may not be fixed.
Steps to Extract Tables with Tabula:


The ‘Export PDF’ function allows you to convert PDF tables directly into a formatted Excel (XLSX) workbook or Word document, often preserving the original styling, fonts, and layout with impressive accuracy. This is the go-to choice for corporate environments where precision and integration with other Adobe products are paramount, but it comes at a significant subscription cost.
- Extremely high accuracy for both native and scanned PDFs.
- Excellent formatting preservation when exporting to Excel.
- Part of a complete PDF editing suite (edit text, images, etc.).
- Trusted and supported by a major company.
Disadvantages:
- Very expensive (requires a monthly or annual subscription).
- Overkill if you only need to extract tables.
- Can be complex and resource-intensive (a large program).
Steps to Extract Tables with Adobe Acrobat Pro:

- Best-in-class OCR accuracy, especially for difficult or low-quality scans.
- Excellent at reconstructing complex table structures.
- Supports a vast number of languages.
- Can handle batch processing of thousands of pages.
Disadvantages:
- High professional price point.
- Can be complex for a casual user to configure for perfect results.
- Slower processing time due to the intensive OCR analysis.

Steps to Extract Tables with ABBYY FineReader:
- Extremely easy to use—just drag and drop.
- No installation required; works on any device with a browser.
- Very fast for simple conversions.
- Many services offer a free tier for occasional use.
Disadvantages:
- Major privacy risk: You must upload your document to a server.
- Often fails on complex tables or scanned PDFs (unless you pay for OCR).
- Free versions have limitations (file size, number of pages, daily uses).
- Requires a stable internet connection.
📊 PDF to Markdown Table Conversion: Tool Comparison
| PDF Input Support | Scanned Image OCR | Free Tier Limits | Paid Tier Benefits | |
|---|---|---|---|---|
| Copilot | ✅ Screenshots only (no direct PDF upload) | ✅ OCR via image input | ⚠️ One image per message; no PDF upload | ✅ Unlimited image input; faster processing; better formatting fidelity |
| ChatGPT | ✅ PDF and image input (GPT-4o only) | ✅ Strong OCR and layout parsing | ⚠️ GPT-3.5 only; no image/PDF support | ✅ GPT-4o access with image/PDF support; enhanced OCR and formatting |
| Grok | ✅ Screenshots or pasted content | ✅ Improved OCR in Grok 3 | ✅ Grok 3 free on x.com/app with quotas | ✅Grok 3/4 tiers unlock extended memory (128K tokens), voice access, image model (Imagine), and AI companions (Ani & Valentine); replaces Think and DeepSearch features |
- You’re working with image-based PDFs or screenshots of tables.
- You need to preserve formatting but don’t want to deal with Excel.
- You want to embed tables directly into Markdown-based documentation or websites.
How to Use AI Tools for Table Extraction:

- Infinitely customizable and powerful.
- Perfect for automating large-batch processing.
- Can be integrated into larger data analysis pipelines.
- Many libraries are free and open-source.
Disadvantages:
- Requires strong technical and programming skills.
- Time-consuming to set up and debug for specific PDF layouts.
- A small change in PDF layout can break the script.
Versatile Convert to Word/Excel/PPT/Text/Image/Html/Epub
Secure 100% local conversions ensure zero risk of data leaks
Efficient Batch Process dozens of PDF files in seconds
Comprehensive Seamlessly convert PDFs to Excel, PowerPoint, Text, and more
OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
Versatile Effortlessly convert XFA, multi
Secure 100% local conversions ensure zero risk of data leaks
Efficient Batch Process dozens of PDF files in seconds

Why can't I just copy and paste a table from a PDF?
What is the absolute best way to extract a table from a scanned (image) PDF?
Are online PDF table extractors safe to use?
Can I extract multiple tables from one PDF file at the same time?
What's the difference between a native PDF and a scanned PDF?
My PDF table has merged cells and complex headers. Which tool is best?
Versatile Convert to Word/Excel/PPT/Text/Image/Html/Epub
Secure 100% local conversions ensure zero risk of data leaks
Efficient Batch Process dozens of PDF files in seconds
Comprehensive Seamlessly convert PDFs to Excel, PowerPoint, Text, and more
OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
Versatile Effortlessly convert XFA, multi
Secure 100% local conversions ensure zero risk of data leaks
Efficient Batch Process dozens of PDF files in seconds
Relate Links :
Converting PDF Files to Excel Using Google Sheets: A Comprehensive Guide

18-04-2025
John Weaver : This article mainly discusses effective methods to convert PDF files into Excel files using Google Sheets. By properly...
How to Convert PDF to Excel Using Google Drive and Docs

15-04-2025
Jennifer Thatcher : Learn how to use Google Drive and Google Docs for converting PDF files to Excel spreadsheets via Google...
How to Convert PDF to Excel Using Excel
10-04-2025
Amanda J. Brook : This article provides a comprehensive guide on importing table data from PDFs into Excel. Additionally, it introduces the...
Edit Scanned PDF Files: Easy Techniques & Pro Tips
03-06-2024
Amanda J. Brook : Learn how to easily edit scanned pdf documents by using PDF format for efficient file transfer and modification.


User Comments
Leave a Comment